 Facebook
Facebook  Twitter
Twitter  Soundcloud
Soundcloud  Youtube
Youtube  Rss
Rss Google has a funky new tool that allows comparative key-word searches of its enormous repository of scanned books. Crudely, this means it is possible to do long-term trends analysis around word usage. A bunch of interesting thoughts on the application of this technology are available here and here.
And just to illustrate the obvious potential of these Google Books Ngram comparisons I have plugged in a few familiar words to see what happens (click on the picture for a larger version).
These initial results are hardly a revelation except that the way mentions of Burma went through the roof in the 1940s and 1950s is somewhat intriguing. Burma has been on a pretty steady downward slide ever since while Thailand has been (mostly) on the up-and-up. Siam continues to bounce along but was recently overtaken by Myanmar. Such is the march of history.
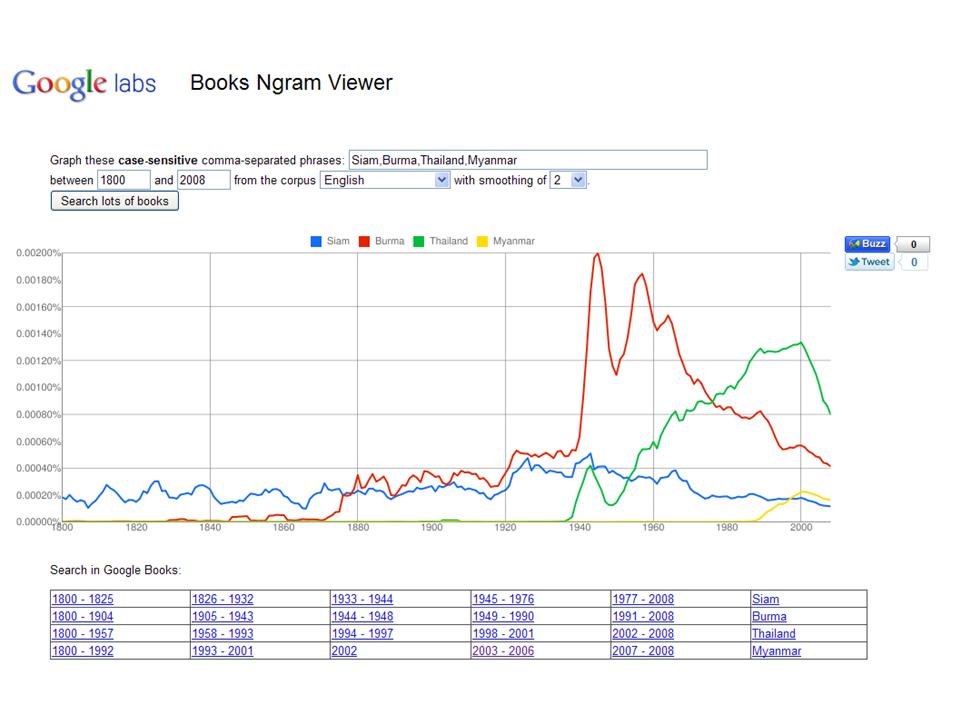
From where I sit, there is endless potential to use this technology (and particularly some of the non-English language functionality) to discern all manner of interesting trends in word and phrase usage.
One of the limitations is the corpus of texts that Google has scanned. Currently the only non-European language in the list is (Simplified) Chinese. We can, however, find out when Russian interest in certain Southeast Asian countries peaked. And there are some subsets of the English language that are also quite exciting. For language usage enthusiasts out there, they could all reward close scrutiny. This Google Ngram, as just one small example, may provide some inspiration.
Thanks, finally, to Sam Roggeveen from the Lowy Institute’s Interpreter for pointing out this terrific blog where I first discovered the magic of the Google Ngram.